Motivation
I was inspired by Revolution's blog and step-by-step tutorial from Jeffrey Breen on the set up of a local virtual instance of Hadoop with R. However, this tutorial describes the implementation using VMware's application. One downside to using VMware is that it's not free. I know most of the people including me like to hear the words open-source and free, especially when it is a smooth ride. VirtualBox offers an open-source alternative and thenceforth, I chose this. Most of the trouble started after a hassle free installation of VirtualBox and creation of the cloudera's demo VM. I came across different hurdles when it came to addition of VirtualBox Guest Additions, which is intended to spruce up the virtual machine by offering such features as a shared folder with the host OS. Although there are solutions, the resources are scattered and obscure. I did manage to clear these hurdles and went on to installing R and RStudio along with RHadoop packages. I thought it would be useful to self-taught enthusiasts like me if I lay out the steps in a comprehensive manner, since I have spent some time dealing with the quirks in the process.
Description
Hadoop
R and Hadoop
The most common way to link R and Hadoop is to use HDFS (potentially managed by Hive or HBase) as the long-term store for all data, and use MapReduce jobs (potentially submitted from Hive, Pig, or Oozie) to encode, enrich, and sample data sets from HDFS into R. Data analysts can then perform complex modeling exercises on a subset of prepared data in R.Revolution Analytics released RHadoop allowing integration of R and Hadoop. RHadoop is a collection of three R packages that allow users to manage and analyze data with Hadoop.RHadoop consists of the following packages:
rmr - functions providing Hadoop MapReduce functionality in R
rhdfs - functions providing file management of the HDFS from within R
rhbase - functions providing database management for the HBase distributed database from within R
Cloudera Hadoop Demo VM
CDH is Cloudera’s 100% open source distribution of Hadoop and related projects, built specifically to meet enterprise demands. Cloudera created a set of virtual machines (VM) with everything we need to make it easy to get started with Apache Hadoop. Cloudera Hadoop's Demo VM provides everything you need to run small jobs in a virtual environment. The packages have been implemented and tested in Cloudera's distribution of Hadoop (CDH3) & (CDH4). and R 2.15.0. This offers a great way to get familiarized with Hadoop.Steps...............
Platforms used in this tutorial:
Guest OS : Mac OS X 10.7.5 (Lion)Virtualization software: VirtualBox 4.2.6
Cloudera Hadoop Demo VM: CDH 4.1.1
R: 2.15.2
RStudio server for : 0.97.248
RHadoop packages: rmr 2.0.2
1. Download and install the latest release of VirtualBox (Ver 4.2.6 at the time of this post) for your platform (Here OS X)
http://download.virtualbox.org/virtualbox/4.2.6/VirtualBox-4.2.6-82870-OSX.dmg
2. Download 'Cloudera's Hadoop Demo VM archive for CDH4
(Latest: Ver 4.1.1 runs CentOS 6.2 64 bit VM)
https://downloads.cloudera.com/demo_vm/virtualbox/cloudera-demo-vm-cdh4.1.1-virtualbox.tar.gz
3. Extract 'Cloudera's Hadoop Demo VM' archive
It extracts virtual machine image file: 'cloudera-demo-vm.vmdk'
4. Copy this virtual machine image to a desired folder (eg:- folder named 'Cloudera Hadoop'). This folder and image file has to be the permanent location of your Hadoop installation (not to be deleted!)
5. We will now create a virtual machine on VirtualBox.
Open application: 'VirtualBox'. Click on 'New'.

Give a name to the VM. Here: 'Cloudera Hadoop'.
Pick type: Linux
Choose version: Linux 2.6 (64 bit)
Click 'Continue'.

It is generally recommended to allocate at least 2 GB of RAM. I recommend more, since I encountered problems installing the R package 'Rcpp' with about 2 GB of RAM. I allocated 4 GB and resolved the issue.
Click 'Continue'.
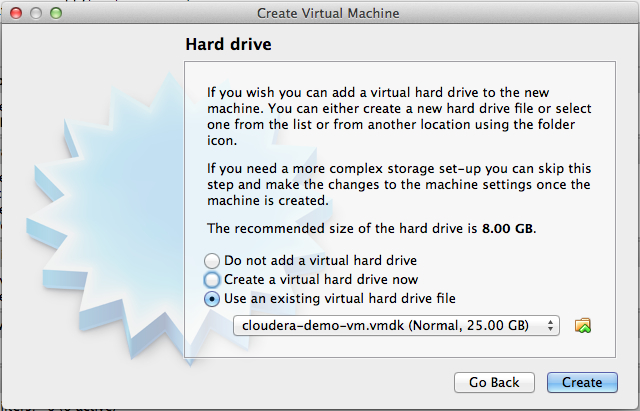
Choose the option 'Use an existing virtual hard drive file' and select the virtual image file ( 'cloudera-demo-vm.vmdk' ) saved in folder 'Cloudera Hadoop' (refer to step 4).
Click 'Create'.
6. Click 'Settings' to make a few recommended changes.

Click on tab 'Advanced' under 'General' category.

Pick 'Bidirectional' option for items: 'Shared Clipboard' and 'Drag'n Drop'

Click on 'System' category. Ensure option 'Enable IO APIC' under 'Extended Features' is checked on (This is default!)
Click on 'Network' category. Choose Adapter 1 option 'Attached to:' as 'Bridged Adapter' (This gives you access to physical wifi. Default is 'NAT')

Click on 'Shared Folders' category. You may choose to pick a folder to share with the host OS (here Mac OS X)

Click 'OK'.

Once you launch the VM, you are automatically logged in as the cloudera user.
The account details are:
username: cloudera
password: cloudera
The cloudera account has sudo privileges in the VM.

There are some prerequisites to installation of 'Guest additions'.
Run console
Switch to root user:
$ sudo bash
Update linux kernel:
$ yum install kernel -y
Reboot
Run console
Open internet browser (Firefox) and download the following file (link below):
http://rpm.pbone.net/index.php3/stat/4/idpl/18259813/dir/scientific_linux_6/com/kernel-devel-2.6.32-220.23.1.el6.x86_64.rpm.html
Click on link for file: kernel-devel-2.6.32-220.23.1.el6.x86_64.rpm
Download and save file to folder 'Downloads' under 'home/cloudera' (Either create new folder using 'Save' dialog box or use console: mkdir /home/cloudera/Downloads
Run console Install packages: $ yum install kernel-devel-2.6.32-220.23.1.el6.x86_64.rpm -y $ yum install gcc -y Link the kernel sources to a standard location using the format: 'ln -s /usr/src/kernels/[current version] /usr/src/linux' $ ln -s /usr/src/kernels/2.6.32-220.23.1.el6.x86_64 /usr/src/linux Installation of package 'dkms' (It is important that you use the steps below to install 'dkms' in CentOS, which is the linux build for your Cloudera demo VM.) Steps to install rpmforge-release package to enable rpmforge repository Run Console $ mkdir rpm (create folder 'rpm' under 'home/cloudera' : /home/cloudera/rpm) $ cd rpm (change to 'rpm' folder: /home/cloudera/rpm) $ wget http://packages.sw.be/rpmforge-release/rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm Install DAG's GPG key $ rpm --import http://apt.sw.be/RPM-GPG-KEY.dag.txt If you get an error message like the following the key has already been imported. error: http://apt.sw.be/RPM-GPG-KEY.dag.txt: key 1 import failed. Verify the package you have downloaded $ rpm -K rpmforge-release-0.5.2-2.el6.rf.*.rpmInstall the package $ rpm -i rpmforge-release-0.5.2-2.el6.rf.*.rpm This will add a yum repository config file and import the appropriate GPG keys. Now install package 'dkms' as root: $ sudo yum install dkmsNow you are ready to download and install 'VirtualBox Guest Additions'. Download 'VirtualBox Guest Additions' .iso image file ('VBoxGuestAdditions_4.2.6.iso') corresponding to your version of 'VirtualBox' installation (in this case Ver 4.2.6).
(Note: The following steps are unlike what is described in most of the posts on this topic.
I faced a lot of problems in making this happen using the steps described in these posts.
I therefore, recommend this method to avoid those issues.)
Open internet browser (Firefox) and download the following file (link below). Save file to folder
'Downloads' under 'home' (already created folder)
http://download.virtualbox.org/virtualbox/4.2.6/VBoxGuestAdditions_4.2.6.iso
Switch to 'root' user: $ sudo bash $ mkdir /mnt/ISO Once your folder is created go to the folder where ISO image 'VBoxGuestAdditions_4.2.6.iso is stored. $ cd /home/cloudera/Downloads Use command: ls to list contents of the folder. $ mount -t iso9660 -o loop VBoxGuestAdditions_4.2.6.iso /mnt/ISO $ cd /mnt/ISO $ ls (lists contents of the mounted 'VBoxGuestAdditions_4.2.6.iso' image) 32Bit cert VBoxSolarisAdditions.pkg 64Bit OS2 VBoxWindowsAdditions-amd64.exe AUTORUN.INF runasroot.sh VBoxWindowsAdditions.exe autorun.sh VBoxLinuxAdditions.run VBoxWindowsAdditions-x86.exe Now install 'Guest Additions' for Linux guest by running the following command. $ sh VBoxLinuxAdditions.run Reboot virtual machine. This completes installation of 'Guest Additions'. (Note: Whenever you reboot, make sure there is network connection. Check the active network icon at the top right corner. If crossed out, click and enable network connection by clicking 'Auto eth0')Enabling network connection at start-up of virtual machine (CentOS)

I learned that the network connection is not enabled automatically at start-up.
This can be resolved by making the following changes.
Run console Switch to root user sudo bash Create/edit the following file: emacs /etc/sysconfig/network-scripts/ifcfg-eth0 This will open up this file in 'emacs' editor. (You will find it blank!) Copy/paste the following into this file. (Hint: use Shift/Cntrl/V to paste!)
DEVICE="eth0"
HWADDR="08:00:27:FE:D5:10"
NM_CONTROLLED="yes"
ONBOOT="no"
Save the file.
Reboot and check if network connection is enabled at start-up (see above).
8. Installation of R First add the EPEL repository, then intall git, wget and R. Find the latest release of the EPEL repository (http://fedoraproject.org/wiki/EPEL) and update the url accordingly. $ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm $ sudo yum -y install git wget R 9. Set Hadoop environment variables so R can find them too! The following is specific for CDH4 Demo VM. $ sudo ln -s /etc/default/hadoop-0.20-mapreduce /etc/profile.d/hadoop.sh $ cat /etc/profile.d/hadoop.sh | sed 's/export //g' > ~/.Renviron 10. Installation of Rstudio server $ wget http://download2.rstudio.org/rstudio-server-0.97.248-x86_64.rpm $ sudo yum install --nogpgcheck rstudio-server-0.97.248-x86_64.rpm 11. Access Rstudio from the browser (you may use any machine in the home network) Check IP address by running command: $ ifconfigAccess RStudio from browser by typing the address (uses port 8787) : e.g., http://10.0.1.15:8787/ Both username and password are 'cloudera' Username: cloudera Password: cloudera12. Installation of RHadoop's rmr package First install the pre-requisite packages. (Run R as root to install system-wide) Run console. $ sudo R R> install.packages( c('RJSONIO', 'itertools', 'digest', 'Rcpp', 'functional', 'plyr', 'stringr'), repos='http://cran.revolutionanalytics.com')R> q() (to quit 'R' session) Download the latest stable release of rmr (2.0.2) from github. Run console $ wget --no-check-certificate https://github.com/downloads/RevolutionAnalytics/RHadoop/rmr2_2.0.2.tar.gz $ sudo R CMD INSTALL rmr2_2.0.2.tar.gz Test that 'rmr2' loads$ R R> library(rmr2) Loading required package: Rcpp Loading required package: RJSONIO Loading required package: digest Loading required package: functional Loading required package: stringr Loading required package: plyr R> 13. Testing with a simple example


small.ints <- to.dfs(1:1000) out <- mapreduce(input = small.ints, map = function(k, v) keyval(v, v^2)) df <- as.data.frame(from.dfs(out))
Screenshot showing execution of above lines on RStudio:

That is great! Thank you for very informative post!!
ReplyDeleteCheers,
Marius
Hello Chandra,
DeleteThank you for update from now onward I start to use this blog in my training practice. Thank you for explaining each step-in screen shots. I use blogs for my easy reference which were quite useful to get started with.
We have an offline mobile app running on iOS11. The work list is presented as a Repeating Dynamic Layout. Pagination is implemented (Progressively load on user scroll). The initial page size is set to 10. The desired behaviour is something like this:
The current behaviour is that all 100 rows are still loaded when the use returns to the work list. We want to reset this to just the first page of records in order to improve the performance of rendering the work list screen. Is there a way to explicitly reset the contents of the RDL to just the first page of data?
Appreciate your effort for making such useful blogs and helping the community.
Thanks,
Nicky
Blog(R): Integration Of R, Rstudio And Hadoop In A Virtualbox Cloudera Demo Vm On Mac Os X >>>>> Download Now
Delete>>>>> Download Full
Blog(R): Integration Of R, Rstudio And Hadoop In A Virtualbox Cloudera Demo Vm On Mac Os X >>>>> Download LINK
>>>>> Download Now
Blog(R): Integration Of R, Rstudio And Hadoop In A Virtualbox Cloudera Demo Vm On Mac Os X >>>>> Download Full
>>>>> Download LINK fg
I followed the instruction but when accessing Rstudio, it keeps giving me prompts that says "cannot connect to service". Just wonder where I went wrong. PS, I cannot log in cloudera with username "cloudera" but username "admin"
ReplyDeleteNever mind. I unpdated the Rstudio manager and now it works well
ReplyDeleteDear Sir,
ReplyDeleteThanks for the article.However when I tried to log into Rstudio it is giving "cannot connect to service " followed by the message R Studio initialization failed.Any idea on how to overcome this error would be greatly helpful
Bingzie Zhang,
can you provide inputs how you resolved this issue
Regs
Anand
This comment has been removed by the author.
ReplyDeletehi after runing above test code I got this error.Please resove tte error
ReplyDeleteError in hadoop.streaming() :
Please make sure that the env. variable HADOOP_STREAMING or HADOOP_HOME are set
> out <- mapreduce(input = small.ints, map = function(k, v) keyval(v, v^2))
Error in save(list = ls(all.names = TRUE, envir = envir), file = name, :
object 'small.ints' not found
> df <- as.data.frame(from.dfs(out))
Error in to.dfs.path(input) : object 'out' not found
> library(rmr2)
> all.ints <- to.dfs(1:1000)
Error in hadoop.streaming() :
Please make sure that the env. variable HADOOP_STREAMING or HADOOP_HOME are set
> out <- mapreduce(input = small.ints, map = function(k, v) keyval(v, v^2))
Error in save(list = ls(all.names = TRUE, envir = envir), file = name, :
object 'small.ints' not found
> df <- as.data.frame(from.dfs(out))
Error in to.dfs.path(input) : object 'out' not found
Really good piece of knowledge, I had come back to understand regarding your website from my friend Sumit, Hyderabad And it is very useful for who is looking for HADOOP.
ReplyDeleteIt was nice article it was very useful for me as well as useful for online Hadoop training learners.thanks for providing this valuable information.123trainings provides best Hadoop online training in uk
ReplyDeleteIt was nice article it was very useful for me as well as useful foronline Hadoop training learners. thanks for providing this valuable information.
ReplyDeleteGood Well works.your article very useful for my projects Thanks a lot.
ReplyDeleteHadoop Training in Chennai
Hi,
ReplyDeleteThanks for nice information and big data hadoop online training provides by experienced experts easy way to learn training with real time on
hadoop online training
I read and performed the steps of your R-Hadoop blog, which is amazing.
ReplyDeleteI ran into a problem. When I run the last lines in the blog
small.ints <- to.dfs(1:1000)
out <- mapreduce(input = small.ints, map = function(k, v) keyval(v, v^2))
df <- as.data.frame(from.dfs(out))
I get the error (connection refused):
packageJobJar: [/tmp/RtmpG4Dchr/rmr-local-env184f5a526c96, /tmp/RtmpG4Dchr/rmr-global-env184f2aee9c99, /tmp/RtmpG4Dchr/rmr-streaming-map184f48d9e2ea, /tmp/hadoop-cloudera/hadoop-unjar5289477608575685863/] [] /tmp/streamjob742667565612512090.jar tmpDir=null
15/03/13 09:55:55 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:55:56 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:55:57 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:55:58 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:55:59 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:56:00 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:56:01 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 6 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:56:02 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:56:03 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 8 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:56:04 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:8021. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
15/03/13 09:56:04 WARN security.UserGroupInformation: PriviledgedActionException as:cloudera (auth:SIMPLE) cause:java.net.ConnectException: Call From quickstart.cloudera/127.0.0.1 to localhost:8021 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
15/03/13 09:56:04 ERROR streaming.StreamJob: Error Launching job : Call From quickstart.cloudera/127.0.0.1 to localhost:8021 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
Streaming Command Failed!
Error in mr(map = map, reduce = reduce, combine = combine, in.folder = if (is.list(input)) { :
hadoop streaming failed with error code 5
Also, when I try to log in to RStudio, I get connection failed error.
Whenever I try to run map reduce jobs, I get the same connection failed error.
I performed every step in the blog using MacOSX 10.7.5 as the host, cloudera quick start VM on Virtual Box.
Thanks so much for your help.
Thank you very much, your blog commenting lists are great help to me in building inbound links to my blog. by VisualPath Technologies is one of the leading Lombardi bpm training centers in Hyderabad and most reputable training division in all areas. The company is dedicated to providing good quality, inexpensive services that will improve the quality of work at all levels of an organization. lombardi bpm
ReplyDeleteNice article i was really impressed by seeing this article, it was very interesting and it is very useful for me.I get a lot of great information from this blog. Thank you for your sharing this informative blog.Hybris Training | Hybris Online Training
ReplyDeleteThanks for the wonderful information and it is useful for Hadoop Learners.
ReplyDeletewe are provide the Hadoop online traiinig.
one again visit site :
hadoop-online-training
thanks for wonderful information & details So, meaningful article i am like this article.
ReplyDeletewe are provide the Hadoop online training
hadoop-online-training
It’s really a nice and useful piece of info.
ReplyDeletePlease stay us up to date like this. Thank you for sharing.For java developers we are offering free Hybris Training
I was reading your blog this morning and noticed that you have a awesome
ReplyDeleteresource page. I actually have a similar blog that might be helpful or useful
to your audience.
Regards
sap sd and crm online training
sap online tutorials
sap sd tutorial
sap sd training in ameerpet
Pretty good post. I just came across your site and wanted to say that I’ve really enjoyed reading your posts. In any case I’ll be subscribing to your feed and I hope you will keep a good work!Cheer!
ReplyDeletesap online training
software online training
sap sd online training
hadoop online training
sap-crm-online-training
There are lots of information about latest technology and how to get trained in them, like Hadoop Training Chennai have spread around the web, but this is a unique one according to me. The strategy you have updated here will make me to get trained in future technologies(Hadoop Training in Chennai). By the way you are running a great blog. Thanks for sharing this (Salesforce Training in Chennai).
ReplyDeleteWell, Good information you have placed and useful too. Just now I saw your blog and it is nice and good maybe we can see more on this. Are you aware of any other websites on this .
ReplyDeleteHamsini Technologies is provide Best HADOOP Training by TOP Industry Experts in Hyderabad with 100% Job Oriented & Placement Record..and
we can provide recorded sessions also.
Free 1st Demo Class,
Contact us : info@hamsinitechnologies.com
Hadoop Online training
I have read your blog, it was good to read & I am getting some useful info's through your blog keep sharing... Informatica is an ETL tools helps to transform your old business leads into new vision. Learn Informatica training in chennai from corporate professionals with very good experience in informatica tool.
ReplyDeleteRegards,
Best Informatica Training In Chennai|Informatica training center in Chennai|Informatica training chennai
Informative article. Helped a lot as I used it in training my students. Thank you, keep writing.
ReplyDeleteSalesforce training institutes in Chennai
Thanks The information which you provided is very much useful for Build Release Training
ReplyDeleteHybris Training
Websphere Commerce Server Training
lombardi bpm Training
Devops Training v
Great information shared on this website. Thanks a lot and keep up the good work and research on hadoop. Regards, hadoop online training
ReplyDelete
ReplyDeleteR is a free software environment for statistical computing and graphics it called "The R Project for Statistical Computing, It compiles and runs on a wide variety of UNIX platforms, Windows and MacOS.
Besant technologies is a most preferred Hadoop Institute in Chennai. This training enables you to build complete, unified Big Data applications combining batch, streaming, and interactive analytics on all their data. With Spark, developers can write sophisticated parallel applications to execute faster and better decisions and real-time actions, applied to a wide variety of use cases, architectures, and industries. We Provide the basic and advance Hadoop Training. http://www.besanttechnologies.com/training-courses/data-warehousing-training/hadoop-training-institute-in-chennai
ReplyDeletereally good piece of information, I had come to know about your site from my friend shubodh, kolkatta,i have read atleast nine posts of yours by now, and let me tell you, your site gives the best and the most interesting information. This is just the kind of information that i had been looking for, i'm already your rss reader now and i would regularly watch out for the new posts, once again hats off to you! Thanks a lot once again, Regards, hybris training in hyderabad
ReplyDeleteHi, I'm having this error in my CM. Error occur again after I redeploy the client configuration. Any idea?
ReplyDeleteException in thread "main" java.lang.RuntimeException: core-site.xml not found
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2476)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2402)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2319)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1057)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1029)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1367)
at org.apache.hadoop.util.GenericOptionsParser.processGeneralOptions(GenericOptionsParser.java:319)
at org.apache.hadoop.util.GenericOptionsParser.parseGeneralOptions(GenericOptionsParser.java:485)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:170)
at org.apache.hadoop.util.GenericOptionsParser.(GenericOptionsParser.java:153)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:64)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at org.apache.hadoop.fs.FsShell.main(FsShell.java:340)
Exception in thread "main" java.lang.RuntimeException: core-site.xml not found
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2476)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2402)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2319)
Excellent Blog ! Got to Learn New things
ReplyDeletehadoop ónlinÉ training
free big data bootcamp
hadoop big data videos
spark ónlinÉ training
Big data QA Tester training
Big data Analyst training
Thanks for all your information.Website is very nice and informative content.
ReplyDeleteSpark Training in Chennai
Step by Step info. Thanks for sharing.
ReplyDeleteCCNA training in Chennai
your basic information is really helpful for beginners and it is useful for developers also thanks for sharing.
ReplyDeletedotnet Training in Chennai
SAP HANA training in hyderabad,This is the best path You can Learn COmplete Course with full fledge knowledge of SAP.SAP HANA training in hyderabad
ReplyDeleteThanks for sharing this informative information. For more you may refer http://www.s4techno.com/hadoop-training-in-pune/
ReplyDelete.NET software development remains one of the best careers, According to polling and surveys. Lots of openings are there in market for Dot net Fresher’s & Experienced Professionals
ReplyDeletedot net training in chennai
All are saying the same thing repeatedly, but in your blog I had a chance to get some useful and unique information, I love your writing style very much, I would like to suggest your blog in my dude circle, so keep on updates.
ReplyDeleteManual testing training in Chennai
Selenium training in Chennai
Software testing training in Chennai
very nice post......
ReplyDeletebe projects in chennai
2016 ieee projects in chennai
java projects in chennai
very nice post......
ReplyDeleteoracle training in chennai
That is very interesting.
ReplyDeleteamazon-web-services training in chennai
Thanks for all your information.Website is very nice and informative content.
ReplyDeleteistqb training in chennai
very nice post......
ReplyDeletemicrostrategy training in chennai
Superb explanation & it's too clear to understand the concept as well, keep sharing admin with some updated information with right examples.Keep update more posts.
ReplyDeleteHome Spa Services in Mumbai
I want you to thank for your time of this wonderful read!!! IOT Training
ReplyDeleteIOT Online Training
Whatever we gathered information from the blogs, we should implement that in practically then only we can understand that exact thing clearly, but it’s no need to do it, because you have explained the concepts very well.
ReplyDeleteBack to original
It's interesting that many of the bloggers to helped clarify a few things for me as well as giving.Most of ideas can be nice content.The people to give them a good shake to get your point and across the command.
ReplyDeleteielts coaching in Chennai
It's interesting that many of the bloggers to helped clarify a few things for me as well as giving.Most of ideas can be nice content.The people to give them a good shake to get your point and across the command .
ReplyDeleteGMAT Training in Chennai
DevOps Training
ReplyDeleteChef Training in Chennai
Ansible training in Chennai
Puppet training in Chennai
Jenkins training in Chennai
C++ Training in Chennai
C Training in Chennai
C++ Training in Chennai
IBM BPM Training in Chennai
Pega Training in Chennai
This blog is gives great information on big data hadoop online training in hyderabad, uk, usa, canada.
ReplyDeletebest online hadoop training in hyderabad.
hadoop online training in usa, uk, canada.
A1 Trainings as one of the best training institute in Hyderabad for online trainings for Hadoop. We have expertise and real time professionals working in Hadoop since 7 years. Our training strategy and materials will help the students for the certification exams also.
ReplyDeleteHadoop Training in Hyderabad
شهر استانبول ،شهر تاریخی و شهر جذاب کشور ترکیه است که در قالب تور ارزان استانبولسالانه پذیرای تعداد زیادی از گردشگران است.اگر قصد سفر به کشور ترکیه را دارید خواهشمندیم برای رزرو تور استانبول با ما در تماس باشید.
ReplyDeleteNice one , Good and very informative blog post. Thanks
ReplyDeleteAndroid Training in chennai | Android Training in chennai
Interesting blog about integration r,rstudio and hadoop in virtualbox which attracted me more.Spend a worthful time.keep updating more.
ReplyDeleteDigital marketing company in Chennai
This comment has been removed by the author.
ReplyDeletewonderful post and very helpful, thanks for all this information. You are including better information regarding this topic in an effective way.Thank you so much
ReplyDeleteSEO Training in Chennai
It's a wonderful post and very helpful, thanks for all this information. You are including better information regarding this topic in an effective way.Thank you so much.
ReplyDeleteAllergy Medicines
Ayurvedic Medicine For Immunity
Hyperpigmentation cream
Viral Fever Medicines
Thank you so much for sharing... apps like lucky patcher
ReplyDeleteReally it was an awesome article...very interesting to read..You have provided an nice article....Thanks for sharing..
ReplyDeleteCloud Computing Training in Chennai
Nice blog. Thanks for sharing such great information.Inwizards Inc is a Hadoop Development services company offers quality Hadoop big data services best in web industries. Intrested click here - Hadoop development services in India
ReplyDeleteGreat and really helpful article! Adding to the conversation, providing more information, or expressing a new point of view...Nice information and updates. Really i like it and everyday am visiting your site..
ReplyDeleteSAP SD Training in Chennai
A great content.
ReplyDeletePYTHON Training in Chennai
Thanks for sharing ...............It's amazing
ReplyDeleteDot net Training in chennai
R-Studio Crack is a Compelling Programming Task to Hint at change lost data From the serious Power You successfully Recover. R-Studio Crack R-Studio Keygen influences a Fortification of the Aggregate hard hover to section or any picked zone Estimations occupation.
ReplyDeleteYour blog is so comprehensive...Almost everything at one place...You have that real PASSION...!
ReplyDeleteBy:grepthor
I simply wanted to write down a quick word to say thanks to you for those wonderful tips and hints you are showing on this site.
ReplyDeleteBest Java Training Institute Chennai
Java Training Institute Bangalore
ReplyDeleteIts really an Excellent post. I just stumbled upon your blog and wanted to say that I have really enjoyed reading your blog. Thanks for sharing....
Carwash in omr
usedcars in omr
automotors in omr
car accessories in omr
The information which you have provided is very good. It is very useful who is looking for
ReplyDeleteJava online training Bangalore
"• Nice and good article. It is very useful for me to learn and understand easily. Thanks for sharing your valuable information and time. Please keep updating IOT Online Training
ReplyDelete"
"• Nice and good article. It is very useful for me to learn and understand easily. Thanks for sharing your valuable information and time. Please keep updating IOT Online Training
ReplyDelete"
Very useful article for me. Thanks for providing this great information.
ReplyDeleteHadoop Big Data Classes in Pune
Big Data Testing Classes
Good Post, I am a big believer in posting comments on sites to let the blog writers know that they ve added something advantageous to the world wide web.
ReplyDeletepython training in chennai | python training in bangalore
python online training | python training in pune
python training in chennai
I would really like to read some personal experiences like the way, you've explained through the above article. I'm glad for your achievements and would probably like to see much more in the near future. Thanks for share.
ReplyDeletejava training in chennai | java training in bangalore
java online training | java training in pune
Thank you for allowing me to read it, welcome to the next in a recent article. And thanks for sharing the nice article, keep posting or updating news article.
ReplyDeletepython training in marathahalli | python training in btm layout
python training in rajaji nagar | python training in jayanagar
Outstanding blog post, I have marked your site so ideally I’ll see much more on this subject in the foreseeable future.
ReplyDeletejava training in annanagar | java training in chennai
java training in marathahalli | java training in btm layout
java training in rajaji nagar | java training in jayanagar
Very nice post here and thanks for it .I always like and such a super contents of these post.Excellent and very cool idea and great content of different kinds of the valuable information's.
ReplyDeleteData Science with Python training in chenni
Data Science training in chennai
Data science training in velachery
Data science training in tambaram
Data Science training in OMR
Data Science training in anna nagar
Data Science training in chennai
Data science training in Bangalore
Wow it is really wonderful and awesome thus it is very much useful for me to understand many concepts and helped me a lot. it is really explainable very well and i got more information from your blog.
ReplyDeleterpa training in Chennai | rpa training in pune
rpa training in tambaram | rpa training in sholinganallur
rpa training in Chennai | rpa training in velachery
rpa online training | rpa training in bangalore
Wow it is really wonderful and awesome thus it is very much useful for me to understand many concepts and helped me a lot. it is really explainable very well and i got more information from your blog.
ReplyDeleterpa training in Chennai | rpa training in pune
rpa training in tambaram | rpa training in sholinganallur
rpa training in Chennai | rpa training in velachery
rpa online training | rpa training in bangalore
Wow it is really wonderful and awesome thus it is very much useful for me to understand many concepts and helped me a lot. it is really explainable very well and i got more information from your blog.
ReplyDeleterpa training in Chennai | rpa training in pune
rpa training in tambaram | rpa training in sholinganallur
rpa training in Chennai | rpa training in velachery
rpa online training | rpa training in bangalore
Needed to compose you a very little word to thank you yet again regarding the nice suggestions you’ve contributed here.
ReplyDeleteData Science training in marathahalli
Data Science training in btm
Data Science training in rajaji nagar
Data Science training in chennai
Data Science training in kalyan nagar
Data Science training in electronic city
Data Science training in USA
Nice blog..! I really loved reading through this article. Thanks for sharing such a amazing post with us and keep blogging...
ReplyDeleteABiNitio online training in Hyderabad
ABiNitio training in Hyderabad
online ABiNitio training in Hyderabad
ReplyDeleteNice blog..! I really loved reading through this article. Thanks for sharing such a amazing post with us and keep blogging...
Hadoop online training in Hyderabad
Hadoop training in Hyderabad
Bigdata Hadoop training in Hyderabad
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.is article.
ReplyDeletepython online training
python training in OMR
python training in Bangalore
python training course in chennai
ReplyDeleteReally it was an awesome article… very interesting to read…
Thanks for sharing.........
Tableau online training in Hyderabad
Tableau training in USA
Best Tableau online training in CANADA
ReplyDeleteThis idea is a decent method to upgrade the knowledge.thanks for sharing
ABiNitio online training in Hyderabad
ABiNitio training in Hyderabad
online ABiNitio training in Hyderabad
This is a terrific article, and that I would really like additional info if you have got any. I’m fascinated with this subject and your post has been one among the simplest I actually have read.
ReplyDeletepython training in tambaram
python training in annanagar
python training in jayanagar
Great website and content of your website is really awesome.
ReplyDeleteSelenium Training in Chennai
selenium course
iOS Course in Chennai
iOS Training Chennai
JAVA Training in Chennai
JAVA Course in Chennai
The content have useful words.
ReplyDeleteaws training in bangalore
aws training in btm layout
Were a gaggle of volunteers as well as starting off a brand new gumption within a community. Your blog furnished us precious details to be effective on. You've got completed any amazing work!
ReplyDeleteData Science Training in Indira nagar | Data Science Training in btm layout
Python Training in Kalyan nagar | Data Science training in Indira nagar
Data Science Training in Marathahalli | Data Science training in Bangalore | Data Science Training in BTM Layout | Data Science training in Bangalore
Awesome Post. I was searching for such a information for a while. Thanks for Posting. Pls keep on writing.
ReplyDeleteInformatica Training institutes in Chennai
Best Informatica Training Institute In Chennai
Best Informatica Training center In Chennai
Informatica Training
Learn Informatica
Informatica course
Informatica MDM Training in Chennai
I really like the dear information you offer in your articles. I’m able to bookmark your site and show the kids check out up here generally. Im fairly positive theyre likely to be informed a great deal of new stuff here than anyone
ReplyDeleteJava training in Chennai | Java training in Tambaram | Java training in Chennai | Java training in Velachery
Java training in Chennai | Java training in Omr | Oracle training in Chennai
Appreciating the persistence, you put into your blog and detailed information you provide.
ReplyDeletesafety courses in chennai
Informative post, thanks for sharing.
ReplyDeleteDevOps certification Chennai
DevOps Training in Chennai
DevOps Training institutes in Chennai
DevOps Training in Adyar
Data Science Course in Chennai
Blue Prism Training Chennai
RPA courses in Chennai
I prefer to study this kind of material. Nicely written information in this post, the quality of content is fine and the conclusion is lovely. Things are very open and intensely clear explanation of issues
ReplyDeletepython training in chennai | python course institute in chennai | Data Science Interview questions and answers
Your blog is very informative. Big data hadoop tutorial is very useful for my work. Keep up the good work.
ReplyDeletehadoop training in chennai
Very nice post here and thanks for it .I always like and such a super contents of these post.Excellent and very cool idea and great content of different kinds of the valuable information's.
ReplyDeleteData Science Course in Indira nagar | Data Science Course in btm layout
Python course in Kalyan nagar | Data Science course in Indira nagar
Data Science Course in Marathahalli | Data Science Course in BTM Layout
Thanks for your efforts in sharing this information in detail. Kindly keep continuing the great work.
ReplyDeleteBest Oracle Training Institute in Chennai
Best Oracle Training in Chennai
Oracle Training Center in Chennai
VMware Training
Vmware Training center in Chennai
VMware Training institute in Chennai
It's really a nice experience to read your post. Thank you for sharing this useful information. If you are looking for more about hadoop training in chennai velachery | hadoop training course fees in chennai | Hadoop Training in Chennai Omr
ReplyDeleteWhen I initially commented, I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails with the same comment. Is there any way you can remove people from that service? Thanks.
ReplyDeleteAdvanced AWS Interview Questions And Answers
Advanced AWS Training in Chennai | Best AWS Training in Chennai
Advanced AWS Training in Pune | Best Amazon Web Services Training in Pune
Very nice post here and thanks for it .I always like and such a super contents of these post.Excellent and very cool idea and great content of different kinds of the valuable information's.
ReplyDeleteangularjs-Training in tambaram
angularjs-Training in sholinganallur
angularjs-Training in velachery
angularjs Training in bangalore
angularjs Training in bangalore
I am a regular reader of your blog and being students it is great to read that your responsibilities have not prevented you from continuing your study and other activities. Love
ReplyDeleteaws Training in indira nagar | Aws course in indira Nagar
selenium Training in indira nagar | Best selenium course in indira Nagar | selenium course in indira Nagar
python Training in indira nagar | Best python training in indira Nagar
datascience Training in indira nagar | Data science course in indira Nagar
devops Training in indira nagar | Best devops course in indira Nagar
Thanks for your contribution in sharing such a useful information. Waiting for your further updates.
ReplyDeleteIELTS Tambaram
IELTS Coaching in Chennai Tambaram
IELTS Classes near me
IELTS Velachery
IELTS Training in Chennai Velachery
IELTS Training in Velachery
IELTS Coaching Centre in Velachery
This information is impressive. I am inspired with your post writing style & how continuously you describe this topic. Eagerly waiting for your new blog keep doing more.
ReplyDeleteAngularjs Classes in Bangalore
Angularjs Coaching in Bangalore
Angularjs Institute in Bangalore
Android Training Center in Bangalore
Android Institute in Bangalore
Awesome Post. It was a pleasure reading your article. Thanks for sharing.
ReplyDeletePega training in chennai
Pega course in chennai
Pega training institutes in chennai
Pega course
Pega training
Pega certification training
Pega developer training
When I initially commented, I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails with the same comment. Is there any way you can remove people from that service? Thanks.
ReplyDeleteAWS Training in Bangalore | Amazon Web Services Training in Bangalore
Amazon Web Services Training in Pune | Best AWS Training in Pune
AWS Online Training | Online AWS Certification Course - Gangboard
Top 10 AWS Interview Question and Answers
thanks for giving that type of information. ielts coaching in gurgaon
ReplyDeleteNice Blog..
ReplyDeletebest training institute for hadoop in BTM
best big data hadoop training in BTM
hadoop training in btm
hadoop training institutes in btm
hadoop course in btm
Its very interesting blog.thank you for sharing this blog
ReplyDeletebest training institute for hadoop in Marathahalli
best big data hadoop training in Marathahalli
hadoop training in Marathahalli
hadoop training institutes in Marathahalli
hadoop course in Marathahalli
Nice Blog
ReplyDeletebest training institute for hadoop in Bangalore
best big data hadoop training in Bangalroe
hadoop training in bangalore
hadoop training institutes in bangalore
hadoop course in bangalore
Thanks for Sharing!!
ReplyDeleteJava Training in Chennai
Python Training in Chennai
IOT Training in Chennai
Selenium Training in Chennai
Data Science Training in Chennai
FSD Training in Chennai
MEAN Stack Training in Chennai
I have read your blog its very attractive and impressive. I like it your blog.
ReplyDeleteappvn app
kajal agarwal hot
Amazing Post. Great write-up. Extra-ordinary work. Waiting for your next Post.
ReplyDeleteSocial Media Marketing Courses in Chennai
Social Media Marketing Training in Chennai
Social Media Training in Chennai
Social Media Marketing Training
Social Media Marketing Courses
Social Media Training
Social Media Marketing Training
Social Media Courses
ReplyDeleteHome Services
Disposal of household insects with natural recipes*Clean the kitchen and arrange it*Clean the living room*Cleaning the bathrooms*House cleaning company in Madinah*Anti-bed bugs*Best colors bedrooms Modern
Furniture Moving Company*Insect Control Company*Insulation Company*Company inspection Villas*Water leak detection company*Company Cleaning Villas*home*Furniture Moving Company
ReplyDeleteThis blog is more effective and it is very much useful for me.
ReplyDeletewe need more information please keep update more.
german classes in bangalore
german language course in bangalore
German Training in Anna Nagar
German Training in T nagar
Hi,
ReplyDeleteI must appreciate you for providing such a valuable content for us. This is one amazing piece of article. Helped a lot in increasing my knowledge.
Best selenium training in chennai
Best selenium Training Institute in Chennai
Selenium classes in chennai
Testing Training in Chennai
Software testing institutes in chennai
Software Testing Training
good work done and keep update more.i like your information's and
ReplyDeletethat is very much useful for readers.
vmware training institutes in bangalore
best vmware training in bangalore
vmware Training in Nolambur
vmware Training in Saidapet
Best technology to open source distributed processing framework Hadoop Training in Chennai
ReplyDeleteVery nice post here and thanks for it .I always like and such a super contents of these post.Excellent and very cool idea and great content of different kinds of the valuable information's.
ReplyDeletebest rpa training in bangalore
rpa training in pune | rpa course in bangalore
RPA training in bangalore
rpa training in chennai
I am very glad to read your great post. Thank you for your worthy info and I want more post. Truely well post and keep blogging...
ReplyDeleteSpoken English Classes in Chennai
Best Spoken English Classes in Chennai
IELTS Coaching in Chennai
Jmeter training in chennai
TOEFL Coaching in Chennai
Ethical Hacking Course in Chennai
Spoken English Classes in OMR
Spoken English Classes in Tambaram
Thanks for the info! Much appreciated.
ReplyDeleteRegards,
Data Science Course In Chennai
Data Science Course Training
Data Science Training in Chennai
Data Science Certification Course
Great Article… I love to read your articles because your writing style is too good, its is very very helpful for all of us and I never get bored while reading your article because, they are becomes a more and more interesting from the starting lines until the end.
ReplyDeletemicrosoft azure training in bangalore
rpa training in bangalore
rpa training in pune
best rpa training in bangalore
Hi, Great.. Tutorial is just awesome..It is really helpful for a newbie like me.. I am a regular follower of your blog. Really very informative post you shared here. Kindly keep blogging.
ReplyDeleteBest Devops training in sholinganallur
Devops training in velachery
Devops training in annanagar
Devops training in tambaram
indian whatsapp group links
ReplyDeleteIts a good post and keep posting good article.its very interesting to read.
ReplyDeleteData Science With R
Authorized macbook pro service center in Chennai | Macbook pro service center in chennai | iMac service center in chennai | Mac service center in chennai | Macbook pro service center in chennai | iphone display replacement
ReplyDeleteWere a gaggle of volunteers as well as starting off a brand new gumption within a community. Your blog furnished us precious details to be effective on. You've got completed any amazing work!
ReplyDeletedevops online training
aws online training
data science with python online training
data science online training
rpa online training
I'm here representing the visitors and readers of your own website say many thanks for many remarkable
ReplyDeleteMicrosoft Azure online training
Selenium online training
Java online training
uipath online training
Python online training
And indeed, I’m just always astounded concerning the remarkable things served by you. Some four facts on this page are undeniably the most effective I’ve had.
ReplyDeleteData science Training in Chennai | No.1 Data Science Training in Chennai
RPA Training in Chennai | No.1 RPA Training in Chennai
AWS Training in Chennai | No.1 AWS Training in Chennai
Devops Training in Chennai | Best Devops Training in Chennai
Selenium Training in Chennai | Best Selenium Training in Chennai
Java Training in Chennai | Best Java Training in Chennai
Awesome Writing. Wonderful Post. Thanks for sharing.
ReplyDeleteBlockchain certification
Blockchain course
Blockchain courses in Chennai
Blockchain Training Chennai
Blockchain Training in Porur
Blockchain Training in Adyar
Its a wonderful post and very helpful, thanks for all this information.
ReplyDeleteVmware Training institute in Noida
thank you for your valuable information
ReplyDeletehttps://mindmajix.com/hadoop/hdfs-architecture-features-how-to-access-hdfs
Attend The Python training in bangalore From ExcelR. Practical Python training in bangalore Sessions With Assured Placement Support From Experienced Faculty. ExcelR Offers The Python training in bangalore.
ReplyDeletepython training in bangalore
As QuickBooks Premier has various industry versions such as retail, manufacturing & wholesale, general contractor, general business, Non-profit & Professional Services, there was clearly innumerous errors that may create your task quite troublesome. At
ReplyDeleteQuickBooks Help & Support, you'll find solution each and every issue that bothers your projects and creates hindrance in running your organization smoothly. Our team is oftentimes willing to permit you to while using the best support services you could possibly ever experience.
Don’t worry we have been always here to aid you. That you can dial our Quickbooks Payroll Support Number. Our QB online payroll support team provide proper guidance to resolve all issue associated with it. I'm going to be glad that will help you.
ReplyDeleteQuickBooks Enterprise has got plenty of alternatives for most of us. Significant quantity of features from the end are there any to guide both both you and contribute towards enhancing your online business. Let’s see what QuickBooks Enterprise Support Phone Number
ReplyDeleteQuickBooks Enterprise has got plenty of alternatives for most of us. Significant quantity of features from the end are there any to guide both both you and contribute towards enhancing your online business. Let’s see what QuickBooks Enterprise Support Phone Number
ReplyDeleteQuickBooks Support Phone Number
ReplyDeleteAnd Decision Making Are you facing the problem with decision making The quantity of are you able to earn in per month You ought to predict this before.
Using the assistance of QuickBooks Tech Support Phone Number, users will maintain records like examining, recording and reviewing the complicated accounting procedures.
ReplyDeleteWe intend to provide you with the immediate support by our well- masterly technicians. A team of QuickBooks Tech Support Phone Number dedicated professionals is invariably accessible to suit your needs so as to arranged all of your problems in an endeavor that you’ll be able to do your work while not hampering the productivity.
ReplyDeleteIf you should be aa QuickBooks Customer Support Number user, it is possible to reach us out immediately at our QuickBooks Support contact number .
ReplyDeleteYou will get regular updates from the software. This will create your QuickBooks payroll software accurate. You won’t have any stress in operation. Even for small companies we operate. This technique is wonderful for a medium-sized company. You may get the most wonderful financial tool. Quickbooks Support Phone Number is present 24/7. You can actually call them anytime. The experts are thrilled to aid.
ReplyDeleteQuickBooks online provides the most reliable accounting experience of this era. When using QuickBooks online with chrome browser, probably the most common errors encountered because of the users is unable to get on QBO account. Usually an error message of loading or service not available pops up. If so you can just dial our toll-free to gain access to our QQuickBooks Support Phone Number to have a quick fix of each QB error.
ReplyDeleteYou will find so many fields it covers like creating invoices, managing taxes, managing payroll etc. However exceptions are typical over, sometimes it creates the negative aspects and user wants QuickBooks Customer Support Phone Number
ReplyDeleteVarious sorts of queries or QuickBooks related issue, then you're way within the right direction. You simply give single ring at our toll-free intuit Quickbooks Support . we are going to help you right solution according to your issue. We work online and can get rid of the technical problems via remote access and also being soon seeing that problem occurs we will fix exactly the same.
ReplyDeleteQuickBooks Enterprise Support Number assists anyone to overcome all bugs from the enterprise forms of the applying form. Enterprise support team members remain available 24×7 your can buy facility of best services.
ReplyDeletea person can very quickly project the sales regarding the business. Our QuickBooks Enterprise Support Phone Number team will really provide you know how to make a projection towards the business concerning the sales it has manufactured in a period period.
ReplyDeletePayroll management is actually an essential part these days. Every organization has its own employees. Employers want to manage their pay. The yearly medical benefit is vital. The employer needs to allocate. But, accomplishing this manually will require enough time. Aim for QuickBooks Payroll Technical Support Number. This can be an excellent software. You can actually manage your finances here. That is right after your accounts software. You'll be able to manage staffs with ease.
ReplyDeletethis can be essentially the most luring features of QuickBooks Enterprise Support Phone Number channel available on a call at .You can quickly avail our other beneficial technical support services easily once we are merely a single call definately not you.
ReplyDeleteHowever, if you are in hurry and business goes down due to the QB error you can easily ask for Quickbooks Consultants or Quickbooks Proadvisors . If you wish to consult with the QuickBooks experts than Intuit QuickBooks Support Phone Number is for you !
ReplyDeleteDo you think you're confident about it? If you don't, this could be simply the right time so you can get the QuickBooks Error Code 6000-301. We now have trained staff to soft your issue. Sometimes errors may possibly also happen as a consequence of some small mistakes. Those are decimals, comma, backspace, etc. Are you go through to deal with this? If you do not, we have been here that will help.
ReplyDeleteSince you understand how important is the QuickBooks payroll to improve your organization, you may need the most effective and trustworthy QuickBooks Payroll assist to avoid facing technical glitches and learn a lot more new things like square QuickBooks integration and QuickBooks online accountant to really make the best utilization of this software using different tools. Just dial QuickBooks Payroll Tech Support Number to perform this phenomenal accounting software without any issue.
ReplyDeleteThanks for giving great kind of information. So useful and practical for me. Thanks for your excellent blog, nice work keep it up thanks for sharing the knowledge.
ReplyDeleteAWS Training in Chennai | AWS Training Institute in Chennai
Thanks for giving great kind of information. So useful and practical for me. Thanks for your excellent blog, nice work keep it up thanks for sharing the knowledge.
ReplyDeleteAWS Training in Chennai | AWS Training Institute in Chennai
If you are a business owner, you really must be aware of the fact that Payroll calculation does demands lot of time and man force. Then came into existence QuickBooks Payroll and QuickBook Support Phone Number team.
ReplyDeleteHow to contact QuickBooks Payroll support?
ReplyDeleteDifferent styles of queries or QuickBooks related issue, then you're way in the right direction. You simply give single ring at our toll-free intuit Phone Number for QuickBooks Payroll Supportt . we are going to help you right solution according to your issue. We work on the internet and can get rid of the technical problems via remote access not only is it soon seeing that problem occurs we shall fix the same.
However, if you are not using this amazing and most helpful QuickBooks Support Phone Number accounting software, then you are definitely ignoring your business success. We give you the best and amazing services about QuickBooks and also provides you all types of information and guidance about your errors or issues in just operating the best QuickBooks accounting software.
ReplyDeleteThe key intent behind QuickBooks Tech Support Number is always to provide the technical help 24*7 so as in order to avoid wasting your productivity hours. This is completely a toll-free QuickBooks client Service variety that you won’t pay any call charges. Of course, QuickBooks is the one among the list of awesome package when you look at the company world.
ReplyDeleteQuickBooks Support Phone Number users in many cases are present in situations where they need to face a number of the performance and some other errors due to various causes within their computer system.
ReplyDeleteQuickBooks Premier is a favorite product from QuickBooks Support known for letting the business enterprise people easily monitor their business-related expenses; track inventory at their convenience, track the status of an invoice and optimize the data files without deleting the info. While integrating this kind of product with other Windows software like MS Word or Excel, certain errors might happen and interrupt the file from opening up.
ReplyDeleteWhile installing QuickBooks Pro at multiple personal computers or laptops, certain bugs shall disturb the initial put up process. This installation related problem could be solved by allowing the executives who will be handling the QuickBooks Support know the details associated with your license and the date of purchase regarding the product to instantly solve the put up related issue.
ReplyDeleteOnce you contact HP Printer Support Phone Number, they are going to quickly show you in resolving HP laptop slow or frozen issues. Meanwhile, here we have show up with a few associated with basic troubleshooting tips to fix all types of issues from the HP Laptops.
ReplyDeleteThe consumer can also eradicate the notebook battery and verify the HP Inkjet Printer Support Phone Number contact points to be sure of the fact that it is not damaged. If still, the matter remains.
ReplyDeleteVery often client faces some typically common issues like he/she isn’t willing to open QuickBooks package, it is playing terribly slow, struggling to install and re-install, a challenge in printing checks or client reports. We intend to supply you with the immediate support by our well- masterly technicians. A group of QuickBooks Technical Support Phone Number dedicated professionals is invariably accessible for you personally so as to arranged every one of your problems in an effort that you’ll be able to do your work while not hampering the productivity.
ReplyDeleteGet notable solutions for QuickBooks in your area straight away! Without having any doubts, QuickBooks has revolutionized the entire process of doing accounting that is the core strength for small as well as large-sized businesses. QuickBooks Tech Support is assisted by our customer support representatives who answr fully your call instantly and resolve your entire issues on the spot. It is a backing portal that authenticates the users of QuickBooks to perform its qualities in a user-friendly manner.
ReplyDeleteTherefore the best, right and easy resolutions would be the most significant for the development of everyone business. So because of this, QuickBooks Support is amongst the great accounting software to easily manage all those things.
ReplyDeleteQuickBooks facilitate for All quite Technical problems You can use QuickBooks to come up with any selection of reports you wish, keeping entries for several sales, banking transactions and plenty of additional. QuickBooks provides a myriad of options and support services for an equivalent. it is commonplace to manage any errors on your own QuickBooks if you're doing not proceed with the syntax, if the code is not put in properly or if you’re having any corruption within the information of the QuickBooks Payroll Support.
ReplyDeleteNeedless to say, QuickBooks Support Number is one the large choice of awesome package within the company world. The accounting area of the a lot of companies varies according to this package.
ReplyDeleteWe all know that the complexity of errors varies from organization to organization. You don’t have to worry for the as all of us is well-aware of the latest software issues and problems. Also, they keep themselves updated with all the most advanced technology and errors introduced when you look at the software on regular time period. You just want to relate genuinely to us on phone by dialing QuickBooks Support Phone Number.
ReplyDeleteThe friendlier approach from the support team shall make a customer contacting them to feel safe and secure in the first place and trust them with the resolving process as well.Even with new bugs and glitches happening every day around the QuickBooks software, the QuickBooks Support Phone Number team stays updated and has the problem-solving skills to remove any kind of barrier that has been disturbing the QuickBooks user in one way or other.
ReplyDeleteQuickBooks Enterprise accounting software is widely used in all the small, medium and large-sized businesses. This is one of the biggest reasons that make this accounting software so popular. Its need is felt everywhere and in a large amount. With QuickBooks Enterprise as a primary software tool for your business, you can work efficiently and save a lot of time and money. Thus, it helps greatly in improving your business productivity. Our QuickBooks Enterprise Support Phone Number to get unlimited technical support. The well-trained, highly capable and experienced technical support experts can resolve your issues and give you the best solutions.
ReplyDeleteThanks for sharing this wonderful information . I really like your post which is useful for every person who requires it. I suggest you to keep posting new information.Fix Outlook Error Code 17897
ReplyDeleteI like your article very much. It has many useful ideas and suggestions. I think it will be more helpful for my research in an efficient manner. Please try to post some more topics as well as possible.
ReplyDeletemachine learning course
This is so amazing post very interesting.Keep sharing dude.Well done.
ReplyDeleteDownload Latest Version R-Studio Web Edition Crack
Attend The Data Analytics Course Bangalore From ExcelR. Practical Data Analytics Course Bangalore Sessions With Assured Placement Support From Experienced Faculty. ExcelR Offers The Data Analytics Course Bangalore.
ReplyDeleteExcelR Data Analytics Course Bangalore
Thanks for sharing this information
ReplyDeleteJava Developer Jobs
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeleteaws Training in Bangalore
python Training in Bangalore
hadoop Training in Bangalore
angular js Training in Bangalore
bigdata analytics Training in Bangalore
python Training in Bangalore
aws Training in Bangalore
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
ReplyDeleteaws Training in Bangalore
python Training in Bangalore
hadoop Training in Bangalore
angular js Training in Bangalore
bigdata analytics Training in Bangalore
python Training in Bangalore
aws Training in Bangalore
I am really happy with your blog because your article is very unique and powerful for new reader.
ReplyDeleteaws Training in Bangalore
python Training in Bangalore
hadoop Training in Bangalore
angular js Training in Bangalore
bigdata analytics Training in Bangalore
python Training in Bangalore
aws Training in Bangalore
I am really happy with your blog because your article is very unique and powerful for new reader.
ReplyDeleteaws Training in Bangalore
python Training in Bangalore
hadoop Training in Bangalore
angular js Training in Bangalore
bigdata analytics Training in Bangalore
python Training in Bangalore
aws Training in Bangalore
As per my opinion, videos play a vital role in learning. And when you consider Big data platform managed service , then you should focus on all the learning methods. Udacity seems to be an excellent place to explore machine learning.
ReplyDeleteThank you for sharing information. Wonderful blog & good post.
ReplyDeleteaws Training in Bangalore
python Training in Bangalore
hadoop Training in Bangalore
angular js Training in Bangalore
bigdata analytics Training in Bangalore
python Training in Bangalore
aws Training in Bangalore
Thank you for sharing information. Wonderful blog & good post.
ReplyDeleteaws Training in Bangalore
python Training in Bangalore
hadoop Training in Bangalore
angular js Training in Bangalore
bigdata analytics Training in Bangalore
python Training in Bangalore
aws Training in Bangalore
Quickbooks is one of such applications which have powerful features and efficient tools for the medium-sized business for User. If you would like to learn How To Resolve Quickbooks Error 9999, you can continue reading this blog.
ReplyDeleteThank you for sharing such a nice and interesting blog with us regarding Java. I have seen that all will say the same thing repeatedly. But in your blog, I had a chance to get some useful and unique information. I would like to suggest your blog in my dude circle.
ReplyDeleteJava training in chennai | Java training in annanagar | Java training in omr | Java training in porur | Java training in tambaram | Java training in velachery
Great post! I am actually getting ready to across this information, It’s very helpful for this blog.thanks for your sharing !!!
ReplyDeleteAndroid Training in Chennai
Android Online Training in Chennai
Android Training in Bangalore
Android Training in Hyderabad
Android Training in Coimbatore
Android Training
Android Online Training
This article really very useful to me..you share through good information from this post!!
ReplyDeleteAndroid Training in Chennai
Android Online Training in Chennai
Android Training in Bangalore
Android Training in Hyderabad
Android Training in Coimbatore
Android Training
Android Online Training
This is the information that have been looking for. Great insights & you have explained it really well. Thank you & looking forward for more of such valuable updates.
ReplyDeleteweb designing training in chennai
web designing training in velachery
digital marketing training in chennai
digital marketing training in velachery
rpa training in chennai
rpa training in velachery
tally training in chennai
tally training in velachery
This is very important and imformative blog for Java . very interesting and useful for students.
ReplyDeletehadoop training in chennai
hadoop training in annanagar
salesforce training in chennai
salesforce training in annanagar
c and c plus plus course in chennai
c and c plus plus course in annanagar
machine learning training in chennai
machine learning training in annanagar
I really enjoyed your blog Thanks for sharing such an informative post.
ReplyDeletehadoop training in chennai
hadoop training in tambaram
salesforce training in chennai
salesforce training in tambaram
c and c plus plus course in chennai
c and c plus plus course in tambaram
machine learning training in chennai
machine learning training in tambaram
Nice article i was really impressed by seeing this article, it was very interesting and it is very useful for me.I get a lot of great information from this blog. Thank you for your sharing this informative blog..
ReplyDeletesap training in chennai
sap training in omr
azure training in chennai
azure training in omr
cyber security course in chennai
cyber security course in omr
ethical hacking course in chennai
ethical hacking course in omr
Thanks for sharing very such great information
ReplyDeleteSEO company toronto
SEO agency toronto
ReplyDeleteNice blog! Thanks for sharing this valuable information
Data Science Courses in Bangalore
Data science course in Pune
Data science course in hyderabad
Data science course in delhi
ReplyDeleteAwesome blog. Thanks for sharing such a worthy information....
Devops Strategy
Why Devops is Important
Very Informative blog thank you for sharing. Keep sharing.
ReplyDeleteBest software training institute in Chennai. Make your career development the best by learning software courses.
Docker classes in Chennai
best devops training in chennai
best msbi training institute in chennai
This comment has been removed by the author.
ReplyDeleteBlog(R): Integration Of R, Rstudio And Hadoop In A Virtualbox Cloudera Demo Vm On Mac Os X >>>>> Download Now
ReplyDelete>>>>> Download Full
Blog(R): Integration Of R, Rstudio And Hadoop In A Virtualbox Cloudera Demo Vm On Mac Os X >>>>> Download LINK
>>>>> Download Now
Blog(R): Integration Of R, Rstudio And Hadoop In A Virtualbox Cloudera Demo Vm On Mac Os X >>>>> Download Full
>>>>> Download LINK xH
thanks for the hardwork you showed in writing this post please see more How To Measure Curtains At Home
ReplyDeleteLiman Restaurant
ReplyDeleteThe Liman Restaurant means port in the Turkish language, however the restaurant opens its doors to all aspects of the Mediterranean kitchen. The kitchen will be mostly focused on Mediterranean food